
In The Context Of Long Context
What happens when you can instantly transform an entire book into a playable simulation? That—and much more—is now possible thanks to the long context revolution.

It was only two months ago that I was writing to you all with news of a fun new feature that we were rolling out at NotebookLM that converted your source material into an engaging simulated audio conversation between two AI hosts. We’d been testing audio overviews internally at Google for the preceding month, so we had a pretty good sense from the enthusiasm we were hearing that we had a hit on our hands. But I think it’s fair to say that we weren’t quite prepared for the magnitude of the reception. I’ve been sharing a lot of it at Twitter if you’re interested in following along, but suffice to say we ended up on CNBC, in late-night talk-show monologues, got named as one of Time’s top inventions of 2024, and generally blew up on TikTok. It’s almost certainly the most viral cultural phenomenon I’ve ever been involved with.
I’ve thought a lot lately about the underlying developments that made audio overviews such a juggernaut: the brilliance of the core prompts that generate the conversation itself (I say "brilliant” because I did not write them!); the uncanny verisimilitude of the AI voices themselves. But there was also the novelty of an AI that seemed to be an expert in whatever documents you had uploaded to your notebook in the first place. If you’ve been reading Adjacent Possible for a while—or you’ve been an early adopter of generative AI—you’ve been aware of and likely interacting with “source-grounded AI” for a year or more. But I think the whole concept had not fully penetrated the broader culture as much as maybe I had assumed. So the sense of wonder (and shock) on the faces of those TikTok creators while listening to an audio overview is not just a reaction to the quality of the conversation; it’s a reaction to experiencing, for the first time, an AI that has some level of familiarity with—even mastery of—your own curated information: your law school reading assignments, your journals, the draft of your novel. You could experience source-grounding via text at a remarkably sophisticated level at Notebook starting in May, when we switched over to Gemini 1.5 Pro and introduced inline citations. But the best way to appreciate that sophistication was to upload a collection of documents, ask a complicated question, get a nuanced answer from the model, and click through the citations to confirm. That could be a powerful experience if you managed to complete those steps, but even if you did, it wasn’t particularly shareable as an experience. Audio overviews, on the other hand, were easily conveyed by social media. And as Andrej Karpathy pointed out, in one of the early tweets about the feature, Audio overviews let you sit back and listen as the AI asked its own questions.
And here’s the thing about source-grounding: the underlying development that makes it possible is the dramatic increase in the size of the model’s context window, the “short-term memory” of the model where the user can supply their own information, as opposed to the “long-term memory” of its training data. When we started working on what became NotebookLM in the summer of 2022, we could fit about 1,500 words in the context window. Now we can fit up to 1.5 million words. (And using various other tricks, effectively fit 25 million words.) The emergence of long context models is, I believe, the single most unappreciated AI development of the past two years, at least among the general public. It radically transforms the utility of these models in terms of actual, practical applications.
One interesting application that we noticed early on in the NotebookLM Discord was that long context was enabling role-playing-game enthusiasts to keep track of their games. You could load in an entire game manual, or the detailed backstory of the campaign you’d authored, and then consult NotebookLM in your capacity as host/Dungeon Master as you played. That was unthinkable in the early days of chatbots, but with NotebookLM’s architecture (and Gemini’s long context) it was as simple as uploading those documents, and asking questions in the chat. At some point early the summer, one user asked in the Discord if anyone had attempted to turn NotebookLM itself into a game-playing platform, where you could actually conduct an entire adventure via the text chat. That sent me off on a long tangent exploring different prompts, and after a week or so I had actually creating a working version of the app that would effectively generate a playable simulation of whatever document you gave it. I created a playable version of The Ghost Map, where you play John Snow trying to solve the mystery of cholera in the streets of London in 1854. I uploaded the wikipedia page for the Cuban Missile Crisis and played through a simulation of those events with me in the role of JFK.
Ever since Google DeepMind introduced the first million-token model earlier this year, I’d been taking notes on an essay that would try to explain why long context is so revolutionary. But playing those interactive simulations gave me an idea: what if I began my long-context essay with a playable game? You’d be able to experience the magic of what these new models are capable of, and then I’d explain what it all means, and where I think it is going to take us. And so I built a mini-game based on one of the chapters from The Infernal Machine; you have to solve the mystery of a Soho break-in using the cutting-edge new forensic science of fingerprint analysis.
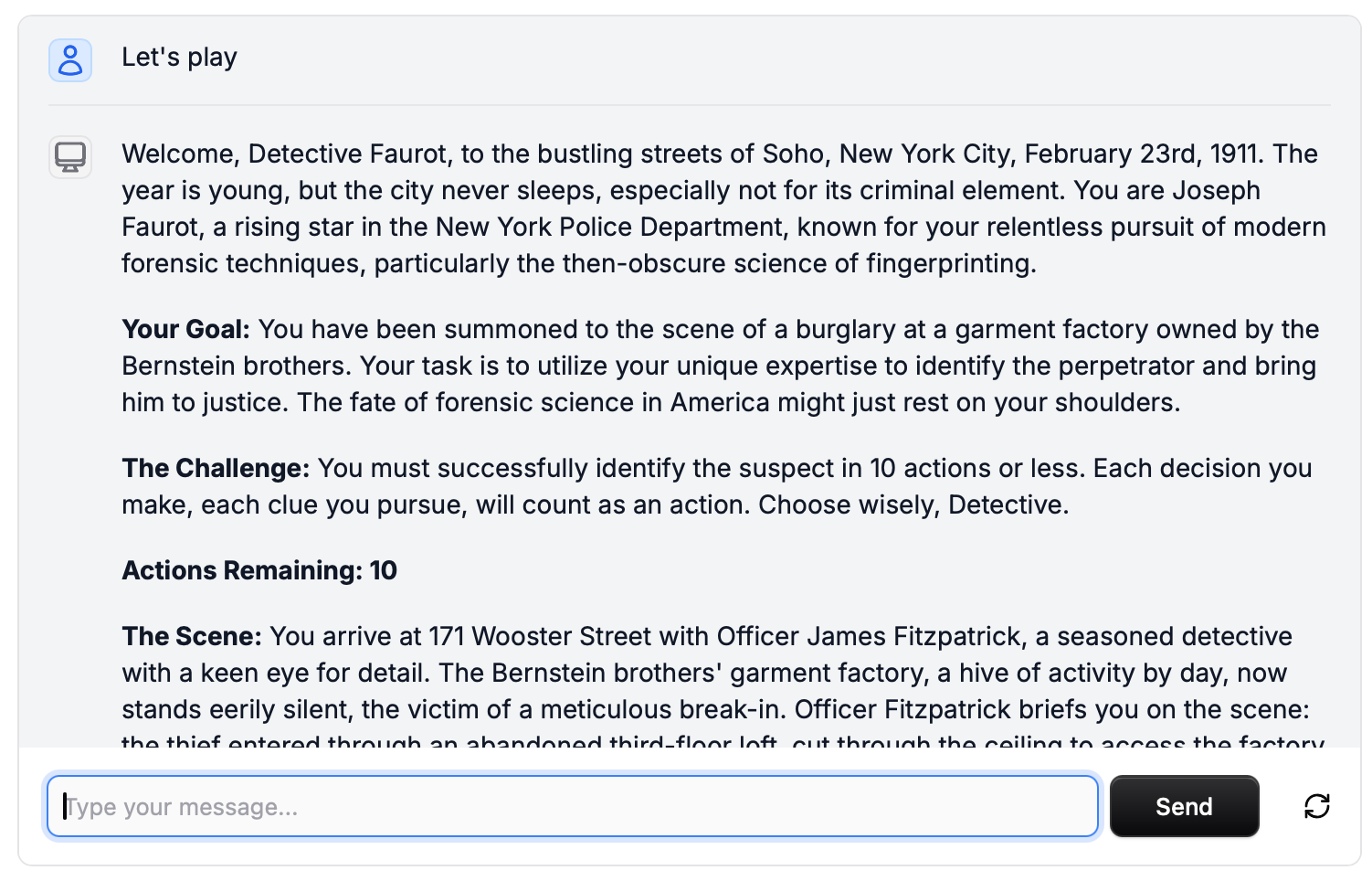
I’ve been working on this essay on the side ever since then, and I’ve just put it online here, as a standalone site. (I couldn’t figure out how to get the game to work in a Substack post, so I collaborated with my son on building the game and the site at a separate URL.) We hope to bring some of this simulation-builder functionality to NotebookLM in the coming months, and of course everything we are working on there is ultimately made possible by these long-context models. Hopefully you can read the whole thing, but I’ll leave you just with the closing paragraphs here, ruminating on some of the possibilities for collective thinking and decision-making in a long context world.
Long context is also a boost for collective intelligence as well. If you assume the average corporate document—a press release, or marketing plan, or minutes from a board meeting—is a few thousand words long, then today’s models can simultaneously hold in their short-term memory close to a thousand documents. A state-of-the-art language model with the ability to instantly recall and generate insights from the most important thousand documents in the history of a company would possess knowledge about that company that would rival that of any single employee, even the CEO. It seems inevitable that anyone trying to make a multi-faceted decision about the future of an organization would want to at least consult such a model. We know from endless studies of social psychology that diverse groups—with different forms of expertise, different pools of knowledge, different cultural backgrounds—tend to make better decisions than homogeneous groups. In a small-context world, you can get some of that diversity from a language model, in that its training data draws from a vast archive of global human knowledge. But a long context model allows you to take that global knowledge and apply it to the unique challenges and opportunities of your own organization. In a matter of years, I suspect it will seem bizarre to draft the specs for a new feature or a company initiative or a grant proposal without asking for feedback from a long-context model grounded in the organization’s history. (And perhaps the public history of its competitors.) It wouldn’t be a replacement for the expertise of the employees; instead, the model would occupy another seat at the table, adding a new kind of intelligence to the conversation, along with a vastly superior recall.
And there’s no reason the organization in question would have to be a corporate entity: maybe it’s a city, or a government agency, or a grassroots advocacy group. Just a year or two ago, asking a small-context model to help chart strategy for, say, a suburban town would have been almost as useless as asking post-surgery Henry Molaison to narrate the preceding six months of his life. Long context gives the model more than just the reasoning and linguistic fluency that emerges through the training process; long context gives the model a specific history to draw from, the idiosyncratic sequence of events that make up the life cycle of any organization or community. Grounded in a long-context history, models are now capable of going beyond just answering factual questions or giving feedback on proposed plans. You might ask the model to identify patterns in a company’s archive to help simulate the way customers or clients would respond to a new product. Or you could draw on the long-context understanding of a city to conduct scenario planning exercises to simulate the downstream consequences of important decisions. Given everything we know about the power of learning through play, you might even take all that contextual history and turn it into a game.
All of which suggests an interesting twist for the near future of AI. In a long-context world, maybe the organizations that benefit from AI will not be the ones with the most powerful models, but rather the ones with the most artfully curated contexts. Perhaps we'll discover that organizations perform better if they include more eclectic sources in their compiled knowledge bases, or if they employ professional archivists who annotate and selectively edit the company history to make it more intelligible to the model. No doubt there are thousands of curation strategies to discover, if that near future does indeed come to pass. And if it does, it will suggest one more point of continuity between the human mind and a long-context model. What matters most is what you put into it.
Read the whole thing (and solve the Soho mystery!) at thelongcontext.com.
I think your game simulation experiments point to a broader range of simulation experiments that would be more than interesting to develop for teaching (teachers curate content to teach) as well as for social science research.
Very interesting stuff Steven.
As a curation scholar I can't but fully agree with your final take on the future:
"In a long-context world, maybe the organizations that benefit from AI will not be the ones with the most powerful models, but rather the ones with the most artfully curated contexts.
Perhaps we'll discover that organizations perform better if they include more eclectic sources in their compiled knowledge bases, or if they employ professional archivists who annotate and selectively edit the company history to make it more intelligible to the model.
No doubt there are thousands of curation strategies to discover...
What matters most is what you put into it."